Examining categorical interactions in logit models using Marginal estimates and Marginsplot
Kevin Ralston 2018, York St John University
Introduction
This post is the third in a series of blogs which examine parameterisations of interactions in logit models. The first post outlined the generic, ‘conventional’ approach to including categorical interactions in logit models. The second post outlined an alternative specification of a categorical interaction in a logit. The current post outlines the application of marginal estimates and the marginsplot graph in the examination of categorical interactions in logit models.
Marginal estimates
Marginal estimates of categorical data are now part of the standard tool box in sociological research outputs. Margins produce estimates which have a ready interpretation. This is helpful because, as we have seen, working out what a model is showing us when an interaction is included is not straightforward. Williams (2017) explains what a marginal probability shows us in a logit model:
In the logit marginal results report the probability that a category is in the category coded 1 on the outcome. The MEM [marginal effect at means] for categorical variables therefore shows how P(Y=1) changes as the categorical variable changes from 0 to 1, holding all other variables at their means.
quietly logit class3 i.sex##i.ft i.qual c.age
margins i.sex#i.ft,
To produce marginal estimates at means we will estimate the basic model we have specified previously. We then follow this with a new line of code which includes the margins command, along with the variables included in the interaction. The quietly command here tells Stata not to produce the output for the model (we’ve seen it already).
Table1, Stata output, marginal estimates at means for an interaction from a logistic regression modelling membership of social class III, including independent variables sex, has a qualification, working full-time or part-time and age, also an interaction between age and working FT/PT. Source is GHS 1995, teaching dataset
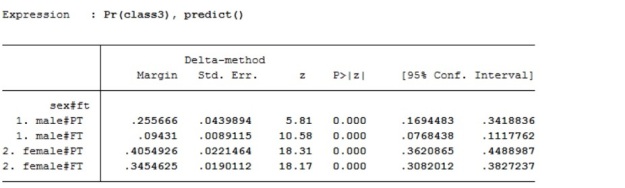
In this case the margins are interpreted as the probability that each of the categories is in social class III at the average value (mean) of the other variables included in the model.
A standard criticism of marginal estimates at means is that the average value at which the estimates are calculated may have no substantive meaning. For example this model includes a categorical measure of whether an individual has qualifications, or not. By coincidence this variable is balanced close to 50% in each category. In a model including say, 30% with no qualifications the average marginal probabilities would be computed for an individual with 30% no qualification. In this model the margins are for an individual with ~50% no qualifications. This is problematic because we are referring to discrete categories. Someone with 50% no-qualifications cannot exist.
quietly logit class3 i.sex##i.ft i.qual c.age
margins i.sex#i.ft, at(qual=1) post,
It is also possible to estimate the marginal at a specific value of independent variables, such as qualifications. These have been described as adjusted predictions or predictive margins. This may be preferred. This is the specification I prefer as it offsets the criticism made above. It does not however mean that anyone in the data necessarily occupies the combination of categories in the model. There may still be no part time male workers with no-qualifications at the mean age of the sample. If there were we would expect them to have a probability of occupying social class III of .178 (quite low, closer to 0 than 1).
Table2, Stata output, adjusted predictions for an interaction from logistic regression modelling membership of social class III, including independent variables sex, has a qualification, working full-time or part-time and age, also an interaction between age and working FT/PT. Source is GHS 1995, teaching dataset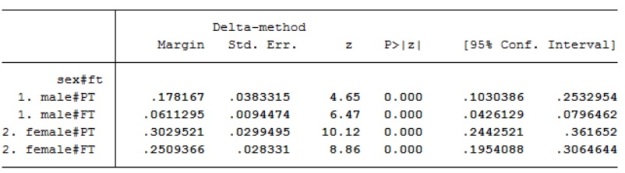
Marginsplot
The margins command has a neat graphing functionality.
Figure1, is a graphic of the marginal probability at means of being in social class III for the working full-time, part-time and sex interaction. The code for this is reported below.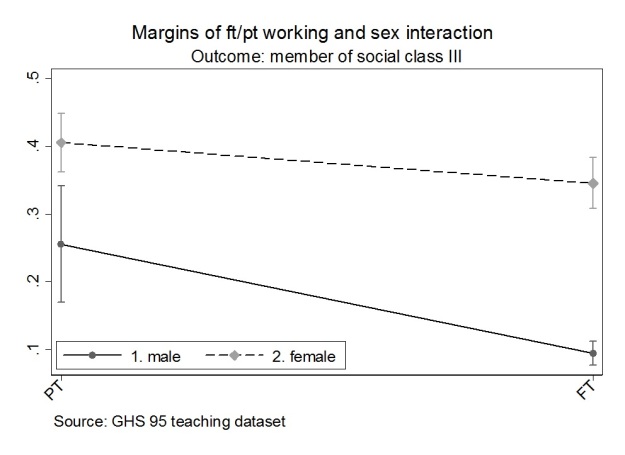
logit class3 i.ft##i.sex i.qual c.age
margins i.ft#i.sex,
marginsplot , name(g2, replace) scheme(s1mono) ///
title (“Margins of ft/pt working and sex interaction”) ///
subtitle(“Outcome: member of social class III”) ///
legend(pos(7) ring(0)) ///
xtitle(“”) ytitle(“”) ///
xlabel(,angle(45)) ///
caption(“Source: GHS 95 teaching dataset”)
To produce this graph you might notice I switched the position of the ft and sex dummy variables in the model. The graphical specification seems more sensible depicting ft/pt on the x-axis and depicting the difference within and between men and women. Maybe I should switch all the models so they are consistent. I had originally included sex in the model first for two reasons. Firstly, people have a biological sex and a socially constructed gender which influences their experience and choices, before they have a full time or part time job. Secondly, gendered occupational segregation is the area of substantive interest.
Building an analysis is an iterative process. There are good reasons to include sex before ft in the model, but in this case the interaction is presented more sensibly when organised i.ft##i.sex. Constructing an analysis often involves making small decisions and trade-offs like this.
Conclusion
In conclusion, I would suggest anyone fitting categorical interactions in logit models should both apply and report the marginal estimates. These have ready and relatively straightforward interpretations. They are certainly more intuitive than the interpretation of the results of a categorical interaction output in Stata applying a conventional interaction in a logit model.
Suggested reference should this post be useful to your work:
Ralston, K. 2018. A categorical can of worms III: Examining categorical interactions in logit models using Marginal estimates and Marginsplot. The Detective’s Handbook blog, Available at: thedetectiveshandbook.wordpress.com/2018/10/15/a-categorical-can-of-worms-iii/[Accessed: 15 October 2018].