An ‘alternative specification’ of a categorical by categorical interaction
Kevin Ralston 2017
Introduction
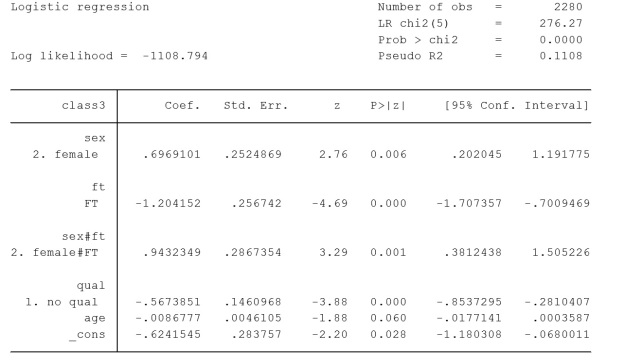
This post outlines an alternative specification of a categorical interaction in a logit. This is the second post in a series which considers options for specifying categorical interactions in logit models. The first post outlined the generic, ‘conventional’ approach to including categorical interactions in logit models. This model included an interaction between sex and full-time/part-time working and is included below as Additional Table 1. In this model the values reported for the sex category and the full-time/part-time category described a contrast between a comparison category and a base category. The base category in an interaction, constructed like this, is a composite of the base category on both the variables included in the interaction. In this case the coefficient for the interaction term reports how much the association changes at different levels of the dependent variables (Kohler and Kreuter 2009). This highlighted that the interpretation of interactions in logit models is different from the interpretation of interactions in ordinary least squares (OLS) models.
Data
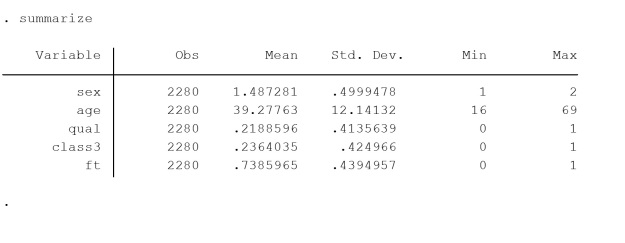
The data used are consistent with the data more comprehensively described in the first blog article which outlined the conventional interaction, and can be found here. The data are from the General Household Survey 1995 teaching dataset (Cooper and Arber 2000) – Table 1. The dependent variable is dichotomous, Register Generals Social Class, controlling for whether an individual is a member of class III or not. Age is included as a linear continuous variable, qualifications is dichotomous, indicating whether an individual has any qualification, or none, sex is a male/female dichotomy, and a final variable controls fulltime or part-time working.
Table 1, distributions of variables of interest
 An ‘alternative’ parameterisation of a categorical by categorical interaction
An ‘alternative’ parameterisation of a categorical by categorical interaction
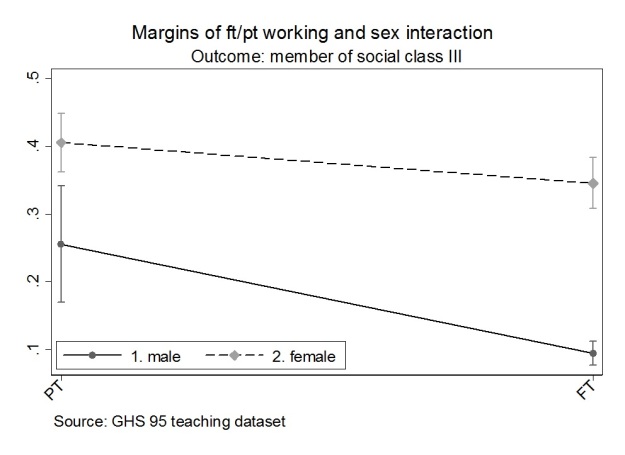
An alternative way to specify this interaction is to generate a model that defines all possible categories of the combination of the categorical variables included in the interaction. I describe this here as an ‘alternative specification’ of the interaction. Examples of this specification were provided in Additional table 2 of the first post, as a means to check comparisons between categories.
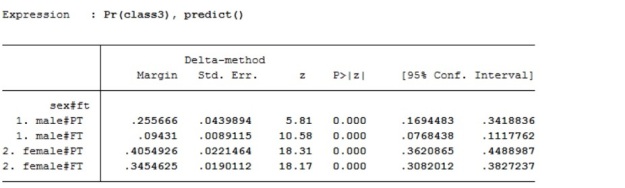
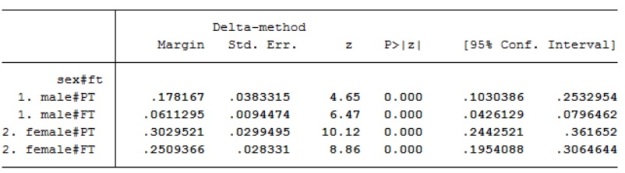
Table 2 displays the alternatively specified interaction. In this instance the model was produced in Stata 13 by placing just one hashtag between the variables to be interacted (i.sex#i.ft). It is also possible to create a composite variable of sex and ft, which is equivalent to this and to include this in the model as a factor variable, or as dummy categories.
The model in Table 2 is statistically identical to the model reported as the conventional interaction (Additional Table 1). For example, log likelihoods and pseudo R2 are exactly the same. The coefficients, and other estimated statistics, for the explanatory variables age and qualification, are also identical between the models. How the interaction term is reported in the model is different, however.
logit class3 i.sex#i.ft i.qual c.age
Table2, Stata output, logistic regression modelling membership of social class III, including independent variables sex, has a qualification, working full-time or part-time and age, also an alternatively reported interaction between sex and working FT/PT. Source is GHS 1995, teaching dataset
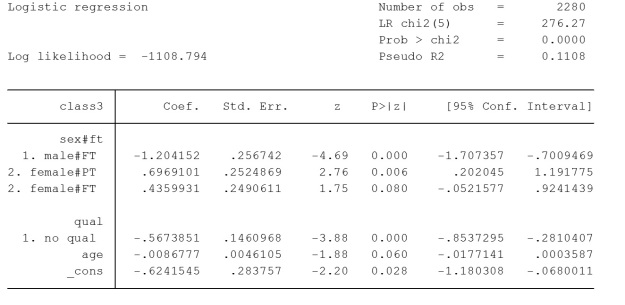
The alternative specification of the interaction variable, in Table2, shows the estimates associated with combinations of categories of sex and working full-time/part-time. There is a reference category and, again, in this instance, it is men working part time. It is often desirable to alter the reference category to check or describe contrasts of interest. In analysis you may choose the reference category depending on numbers of cases in the category. Sometimes there may be a gradient of increasing estimates which tells a story and is neat to show. Alternatively, you may choose the reference category because the contrasts are important to answer a research question.
Here the male/part-time category is the reference category and is contrasted male/FT, female/PT and female/FT. In the model it can be seen that the coefficients for male/working full-time and female/working part time are the same as the coefficients, reported in the conventional interaction (Additional Table 1), for the coefficient values for sex and ft. The interaction in Table 2 also contains a category of females/working full-time which is non-significant, in contrast to the reference category.
The interaction as specified in Additional Table 1 is conventional in the sense that it is specified in a manner in which interactions in OLS models are generally specified. I find the alternative specification, in Table 2, preferable in helping to think through what a categorical by categorical interaction is showing. This parameterisation is not discussed by Kohler and Kreuter (2009) and Royston and Sauerbrei (2012) do not recommend this. In my view the alternative specification provides more clear information. In this specification it is immediately apparent what the reference category is and what the contrasts represent.
It is also useful to switch the reference category used and/or to estimate quasi-variances (see Connelly 2016) to check substantive associations. If you do this and take time to think through the results, then you are likely to build a strong understanding of the associations the model is representing. You are also likely to catch mistakes.
Conclusions
This post outlines an ‘alternative specification’ for including categorical by categorical interactions in a logit models. This is contrasted with a conventional specification (from the first post in this series). The alternative specification is shown to have a benefit over the conventional specification in that there is an intuitive interpretation for the levels of the interaction. As part of a sensitivity analysis I currently recommend that a researcher should model a categorical interaction using a range of specifications, including the ‘alternative specification’ outlined here. Being able to see levels of the interacted variables, along with significance, in comparison to the reference, allows an analyst to usefully assess substantive as well as statistical importance. It is also possible to publish a model applying interactions specified in this way (e.g. Ralston et al. 2016; Popham and Boyle 2011).
References
Cooper, H. and Arber, S. 2000. General Household Survey, 1995: Teaching Dataset. [data collection]. 2nd Edition.
Kohler, U. and Kreuter, F. 2009. Data Analysis Using Stata: Second Edition. College Station, Tx: Stata Press.
Popham, F. and Boyle, P.J. 2011. Is there a ‘Scottish effect’ for mortality? Prospective observational study of census linkage studies. Journal of Public Health 33(3), pp. 453–458.
Ralston, K. et al. 2016. Do young people not in education, employment or training experience long-term occupational scarring? A longitudinal analysis over 20 years of follow-up. Contemporary Social Science, pp. 1–18.
Royston, P. and Sauerbrei, W. 2012. Handling Interactions in Stata, especially with continuous predictors. . Available at: http://www.stata.com/meeting/germany12/abstracts/desug12_royston.pdf.
Additional Table 1, Stata output, logistic regression modelling membership of social class III, including independent variables sex, has a qualification, working full-time or part-time and age, also an interaction between age and working FT/PT. Source is GHS 1995, teaching dataset