Alana McGuire, University of Stirling, 2016
Background
This blog is based upon work being undertaken for a PhD at the University of Stirling which explores the impact of Big Data on skill requirements for employers in Scotland. A version of this article was presented as a poster at the National Centre for Research Methods Festival, Bath, July 2016. The project research design applies mixed methods using a hybrid adaption of the explanatory sequential design (Creswell and Clark, 2011). Questions the study will address include: How is Big Data changing skill demands for employers? Is data becoming a more central part of organisations, and if so, is this causing changes in the job roles of employees in the organisation? Are there discrepancies between the skills that employees are being equipped with on training courses and the skills that employers are seeking? Is there evidence of social/gender/ethnic inequalities in Big Data skills?
The definition of Big Data is contested. The term ‘Big Data’ in the context of this project refers to complex data that requires a change in what is actually perceived as data (Lagoze, 2014). This may be structured in a conventional dataset or unstructured, for example, data from a health device or Twitter. This can also take a variety of formats. The size of the data itself is not the defining characteristic for the purposes of my research.
Mellody (2014: 10) argues that the main skills needed to work with Big Data are ‘computing and software engineering’, ‘machine learning’ and ‘optimization’. Machine learning focuses on ‘how to get computers to program themselves’ (Mitchell, 2006: 1). By optimization, Mellody is referencing ‘database optimization’, that is the programing of the database so that commands are executed and results obtained in the quickest way possible (Mullins, 2010). As well as these skills, Yiu (2012) argues that Big Data specialists must also have ‘soft’ skills such as good communication, collaboration and creativity. Further to this, Yui suggests critical consumption of data and statistical methods are skills which have been neglected by the literature exploring the abilities needed to work with Big Data. Although needs for these skill may not be unique to Big Data, it is essential when working with Big Data that the analyst understands which methods are appropriate and how to interpret output from these.
Routinely collected and deposited data sources, such as the Labour Force Survey (ONS, 2016), do not capture variables which encompass the combination of skills discussed in the literature as necessary in the practice of analysis using Big Data. A key issue is therefore to find proxies that can robustly measure Big Data skills. Given this dearth of resources a plausible alternative strategy may be available in the Employer Skills Survey (ESS). These data contain some information on skills shortages which can be used to assess need within sectors of the economy, for example, data on numeracy, IT, and communication skill shortages (see UK Commission for Employment and Skill, 2016). In addition to the ESS, the 1970 British Cohort Study (BCS) tested ability in maths, several of the items used in this test are related to those abilities considered definitive of Big Data skills.
This remainder of this post outlines two proxy measures that could be relevant to understanding the prevalence of skills associated in working with Big Data.
Data and Methods
The Employer Skills Survey is a large scale survey conducted annually by the UK Commission for Employment and Skills (2016). For the 2013 survey, 91,279 interviews were completed. This survey is one of the largest of its kind in the UK, providing a wealth of data surrounding skills shortages in the UK.
The Employer Skills Survey was used to define a variable that measures the basic skills that are needed in an industry in order to potentially make use of data in that industry. This was given the form of a score, constructed from several skill shortage variables, these included, communication, numeracy, and IT skills. Graph 1, below, shows the distribution of this variable. The skill score variable has a mean of 1.89 and a range of between zero and six, zero being indicative of no difficulty finding Big Data base skills and six being indicative of having difficulty finding every one of the big data base skills. Should an industry score highly on this variable this can be considered to indicate that the particular industry or organisation finds it difficult to recruit employees with skills identified as necessary for working with Big Data. It would be particularly problematic if the industries lacking these skills were ones which could benefit from the analysis of Big Data.
Graph 1
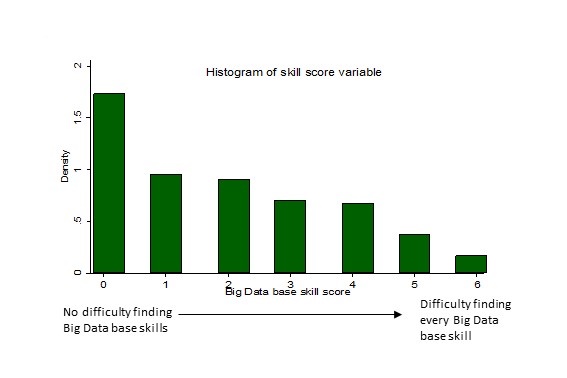
Applying this variable makes it is possible to make an assessment of industries, or sectors, which may be experiencing a shortfall in recruitment of the core skills. A simple analysis is presented using OLS regression controlling the organisation type, comparing non-market organisation and profit making companies, the size of the organization, being an SME (small/medium sized enterprise) or not, whether the organisation is based in Scotland, compared to the rest of the UK and an interaction term between being based in Scotland and being an SME. If there is a skills shortfall of this type the effort and expenditure required to upskill staff from a poor basis would be far greater.
Alongside the Employer Skill Survey analysis, I have undertaken some initial analysis using the British Cohort Study. This study takes a group of babies born in a week in 1970 and follows these individuals throughout their lives. There was a follow up study to this which gave an arithmetic test to a sample of the cohort at aged sixteen. Many of the questions in this test are highly relevant for understanding statistics and data distributions. Further to this, there are also datasets from later studies which contain socioeconomic information on the same individuals. One avenue for these data in my study is to consider the score on the arithmetic tests as proxy for Big Data skills. This presumes that statistical literacy is a key element of Big Data skills and at the moment it is unclear that this is the case. If we make an assumption that mathematical and statistical abilities are important aspects of working with big data, then the distribution of these skills in the population could relate to whether sectors of the economy are able to tap into these skills. National statistics, scocio-economic classification (NS-SEC) 7 class is used to estimate the level of these skills by social class. The NS-SEC social class measure was captured during follow up to the original study, done in 2004/05 (University of London, 2016b). At this point individuals would have reached an age of occupational maturity (around 34 years of age) (Goldthorpe, 1987).
Results and Discussion
Table 1 presents the results of an analysis of the ESS using OLS regression. The skill score variable described above is set as the dependent variable. As described above, dummy variables are included which control for the comparison between a non-market organisation and a profit making company; being an SME or not; based in Scotland, compared to the rest of the UK; and an interaction term between being based in Scotland and being an SME. The associations for non-market organisations and SMEs are statistically significant which suggests that organisations with these characteristics are more likely to have fewer employees with a skill base capable of working with Big Data. This resonates with findings reported by E-Skills UK (2013) which suggests that SMEs are far less likely to make use of Big Data. Being based in Scotland is not significant and neither is the interaction term, suggesting that organisations located in Scotland are not any more likely to lack the Big Data base skills than organisations located elsewhere in the UK. Testing whether is finding is consistent is an important focus for my wider PhD study.
Table 1, OLS regression results, the dependent variable is the Big Data base skill score
| Coefficient | Standard error | P-value | |
| Non market | .554 | 0.098 | 0.000 |
| SME | .233 | 0.082 | 0.005 |
| Scotland | .003 | -0.35 | 0.989 |
| SME*Scotland | -.154 | -0.64 | 0.532 |
| Constant | 1.659 | 1.53 | 0.000 |
I used the BCS to examine whether there are any suggestions in the data of social, gender, and ethnic inequalities in the distribution of the maths test results. In order to do this, I looked at correlations between arithmetic scores from 1986 (University of London, 2016a) and later data from the module including measures of social class. Graph 2 shows the mean arithmetic scores with confidence intervals form 1986 with NS-SEC from 2004/05. In this graph, routine occupations is the lowest occupational social class in the NS-SEC in this data and higher managerial is the highest. A gradual decline of arithmetic scores in line with declining NS-SEC occupational social class is evident. This is indicative of a possible social divide in Big Data skills. Albeit this only holds if statistical skills are a good indicator of Big Data skills and more research on my part is necessary to find out if this is the case.
Graph 2

Conclusion
This post has proposed two proxy measures of Big Data skills using data from the Employer Skill Survey and the British Cohort Study. These proxies may be relevant for measuring the prevalence of Big Data skills in the general population and for assessing how social stratification relates to Big Data skills. Going forward, more research is needed to ensure that these measures are robust.
This work provides a starting point for me to examine social, gender, and ethnic inequalities in Big Data skills. Alongside my statistical analysis, I will be supplementing this with qualitative research in the form of interviews with skills providers, employers, and employees. My statistical measures will be revisited after interviews to examine if the measures that I have used thus far are valid proxy variables for Big Data skills. If this is not the case, I will collect additional primary data which can then be used in my analysis. I would be glad to receive any constructive feedback in respect of my study and to hear from anyone working on a related topic.
Acknowledgements: I would like to acknowledge the help of my project supervisors, Dr Alasdair Rutherford and Professor Paul Lambert, I would also like to thank Dr Roxanne Connelly for suggestions made for this paper, and the PhD is funded by the ESRC.
Blog: https://alanainprogress.wordpress.com/
Twitter: @_AlanaMcGuire
Email: alana.mcguire@stir.ac.uk
References
Creswell, J.W., and Clark, V.L. (2011). Designing and Conducting Mixed Methods Research. Sage: London
Tashakkori, A., and Creswell, J.W. (2007). The new era of mixed methods. Mixed Methods Research. 1: pp.3-7.
E-Skills UK. (2013) Big Data Analytics: Adoption and Employment Trends, 2012-2017. Accessed online at <http://www.e-skills.com/Documents/Research/General/BigDataAnalytics_Re port_Nov2013.pdf>
Goldthorpe, J. H. (1987) Social Mobility and Class Structure in Modern Britain, 2nd edition. Oxford: Clarendon Press.
Lagoze, C. (2014) Big Data, data integrity, and the fracturing of the control zone. Big Data & Society, pp.1-11.
Mellody, M. (2014). Training Students to Extract Value from Big Data: Summary of a Workshop. National Research Council.
Mitchell, T. (2006) The Discipline of Machine Learning. Accessed on 09/12/15 at <http://www.cs.cmu.edu/~tom/pubs/MachineLearning.pdf>
Mullins, C. (2010) Defining Database Performance. Database Trends and Applications. Accessed on 9/12/15 at <http://www.dbta.com/Columns/DBA-Corner/Defining-Database-Performance-70236.aspx>
Office for National Statistics. Social Survey Division. (2016). Quarterly Labour Force Survey Household Dataset, January – March, 2016. [data collection]. UK Data Service. SN: 7991, http://dx.doi.org/10.5255/UKDA-SN-7991-1
UK Commission for Employment and Skills. (2016). Employer Skills Survey, 2013. [data collection]. 2nd Edition. UK Data Service. SN: 7484, doi: http://dx.doi.org/10.5255/UKDA-SN-7484-2.
University of London. Institute of Education. Centre for Longitudinal Studies. (2016a). 1970 British Cohort Study: Sixteen Year Follow-up, Arithmetic Test, 1986. [data collection]. 2nd Edition. UK Data Service. SN: 6095, doi: http://dx.doi.org/10.5255/UKDA-SN-6095-2.
University of London. Institute of Education. Centre for Longitudinal Studies. (2016b). 1970. British Cohort Study: Thirty-Eight-Year Follow-Up, 2008-2009. [data collection]. 4th Edition. UK Data Service. SN: 6557, doi: http://dx.doi.org/10.5255/UKDA-SN-6557-3.
Yiu, C. (2012). The Big Data Opportunity. Policy Exchange. Accessed online at <http://www.geomapix.com/pdf/big%20data.pdf>
