A Mediation analysis of a Poisson outcome with a binary mediator in Stata, using the PARAMED module
Kevin Ralston 2019, York St John University
This blog examines options available to undertake Mediation analyses in packages SPSS, R and Stata. Mediation analysis is a growing area of interest and the blog considers the case of undertaking a Mediation of a count outcome with a binary categorical mediator. It is shown that the functionality to undertake analysis of these data is available in all three packages and an example is given for Stata.
Background
During the long summer of 2018 a colleague contacted me asking if I knew how to undertake Mediation analysis. Off the top of my head I did not, but a few years ago I had attended a course on causal modelling in Stata (it was a later version of this course). The functionality demonstrated on the course had just become possible in the most recent versions of Stata (13 I think). I had a couple of meetings with Dr Davis, who led the research, where it was explained what was needed.
It was very interesting. They are psychologists studying the adult experience of hallucinations and whether this is predicted by childhood imaginary play partners (imaginary friends). They wanted to know whether the relationship they observed in modelling, between having an imaginary friend in childhood and subsequent experience of hallucinations in adulthood, was mediated by having experienced abuse (‘childhood adversity’).
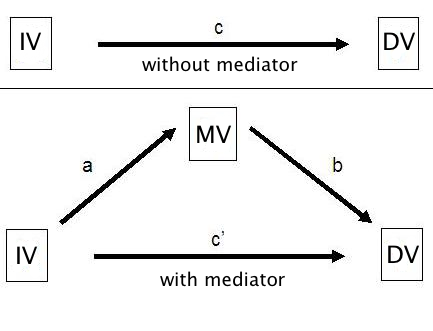
Sharma (2015) explains that Mediation analysis refers to the ‘estimation of the indirect effect of X on Y through an intermediary mediator variable M causally located between X and Y (i.e., a model of the form X → M → Y)’. Or, as the graphic below describes IV → MV → DV.
This is exactly what they were looking to do. There were some complications however, they wanted the outcome variable to be modelled as a Poisson count of level of hallucination severity, the mediator was a binary indicator of abuse and the explanatory variable was also a binary indicator of whether the individual had an imaginary childhood friend. There were additional categorical control variables of gender and income.
Finding an appropriate model
Mediation analysis has a long history. A version of mediation analysis was outlined by Sewall Wright in 1934. As is often the case with statistical methods, although extremely clever people were able to demonstrate the possibility of a method several generations ago, this is unfortunately not equivalent to making the method accessible to those of lesser mathematical knowledge. Indeed, it is only in the last decades that the application of mediation analysis has expanded in fields such as psychology. This has been contingent on the growth of computing power along with software which renders these tools accessible to applied analysts. Even given current computer power and the ability of standard statistical software to handle mathematical models of increasing complexity, Mediation analysis has only relatively recently been absorbed into the most commonly used statistical packages.
R is very versatile and can handle a substantial range of data and models via recently released packages such as mediation:R. Those involved in statistical analysis know that R is a fantastically powerful software. The main drawback is that it requires a relatively high threshold of user knowledge to work in the environment. Stata comes somewhere between SPSS and R. To undertake analysis Stata requires more of a learning curve than SPSS but offers superior functionality and modelling capability. It offers less versatility or modelling capability than R, but nevertheless offers a wide variety of possibilities that are likely to meet the needs of most social-scientists.
Mediation:R would certainly do what we needed, but my experience as an analyst in R is that running into a problem in the package leads to substantial project delay. The knowledge threshold that R requires is comparatively high so that overcoming problems demands substantial outlays of time and mental capacity. This is not in itself an issue, but sometimes you have time to spend, and sometimes you need a result! My colleagues wanted the final piece of analysis for their paper.
A presentation by Grotta and Bellocco provided the solution in Stata. The presentation outlined several approaches to Mediation analysis including the PARAMED module. PARAMED enables Mediation analysis of categorical dependent variables such as our Poisson outcome. Checking the documentation that accompanied the installed module it allowed for exactly the model my colleagues needed. It also turned out that the PARAMED module is based on SAS and SPSS macros for running Mediation. Therefore the PARAMED functionality has equivalent in both SAS and SPSS.
I cannot claim to be a deep expert in SPSS but that is the package the team were working in. They were taking a look at the SPSS package PROCESS. I understand that the SPSS PROCESS package, has been written to allow Mediation analysis and version 3 handles categorical dependent variables. The developer of the PROCESS macro points to their book, Introduction to Mediation, Moderation, and Conditional Process Analysis for those interested in using this. Although it looks as though the analysis would be possible in PROCESS I have not yet found an instantiation, but there may well be one in the book.
It is apparent that functionality to undertake the modelling required is generally available. Stata is my preferred package and an example of a Mediation analysis in Stata is given below.
Analysis
The analysis used Stata 15. Variables specified in the analysis are listed below. The variable names are somewhat esoteric, sorry about that:
- UHRSUMPER is the count measure of hallucination
- ICTWOWAY is the binary measure of imaginary childhood companion (described as CIC status – childhood imaginary companion)
- SUMADVERSITY2WAY is the binary indicator of abuse
- Income is in three categories
- Male is binary men and women
The first thing I did was to install PARAMED and check the documentation, help files.
ssc install paramed
help paramedI tried various model specifications, starting most simply.
The Stata code below specifies the full model:
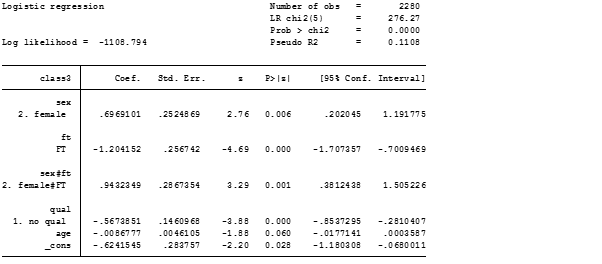
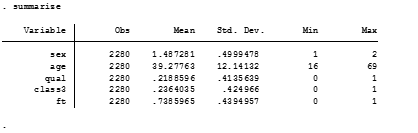
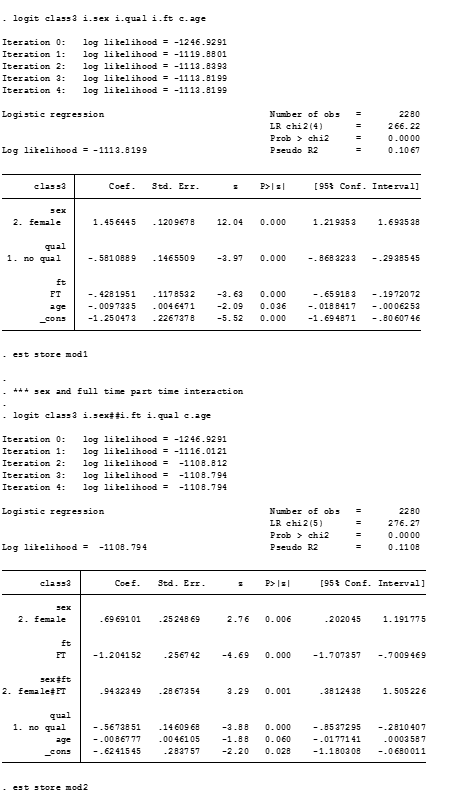
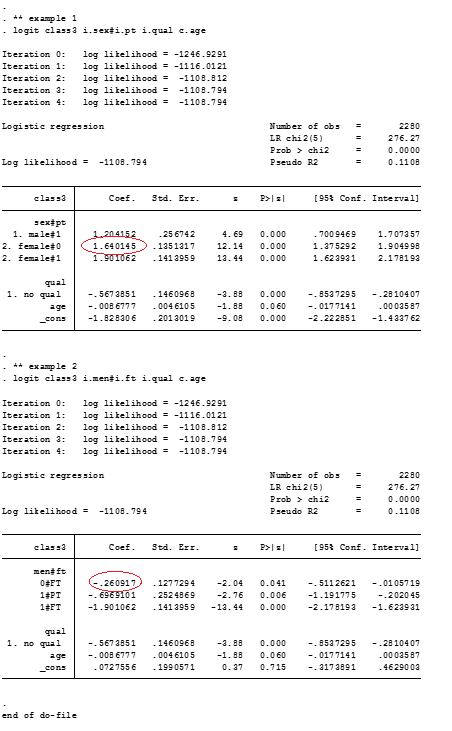
paramed UHRSUMPER, avar(ICTWOWAY) mvar(SUMADVERSITY2WAY) cvars(under10k ten_25k male) a0(0) a1(1) m(1) yreg(poisson) mreg(logistic) nointer boot seed(1234)
paramed invokes the paramed routine in Stata, yreg(poisson) specifies that the dependent variables is a count, mreg(logistic)specifies the mediator as binary. cvars(under10k ten_25k male) are dummy categories for the dummy variables of sex and income. The code a0(0) a1(1) m(1) specifies levels of the explanatory variable and the mediator. boot specifies whether a bootstrap procedure should be performed to compute bias-corrected bootstrap confidence intervals and seed specifies the seed for the bootstrap.
Mediation results output from Stata
| Estimate | Std Err | P>|z| | Lower 95% confidence Interval | Upper 95% confidence Interval | |
|---|---|---|---|---|---|
| cde | 1.253955 | .10531446 | 0.032 | 1.0200853 | 1.5414429 |
| nde | 1.253955 | .10531446 | 0.032 | 1.0200853 | 1.5414429 |
| nie | 1.088400 | .03164556 | 0.007 | 1.0229427 | 1.158046 |
| mte | 1.3648047 | .10552532 | 0.003 | 1.1098021 | 1.6784 |
mte=Total effect, nde=Natural direct effect, nie=Natural indirect effect
Conclusions
This blog has discussed some options available to undertake Mediation analyses in packages SPSS, R and Stata. An example of a potentially problematic Mediation analysis of a Poisson outcome has been outlined and it is shown that Stata was able to handle a tricky model like this via the user written program, PARAMED. In addition to giving readers an insight into options available to those interested in Mediation analysis the blog provides an opportunity to give due credit to the authors of the PARAMED module, Richard Emsley and Hanhua Liu. Unfortunately the journal that published the research article would not allow the inclusion of the reference for the PARAMED module, although we were able to name check the module in the text of the article. I have uploaded a pre-publication version of the paper with the reference attached and the full reference is provided below. Thank you Professor Emsley and Dr Hanhua Liu.
The co-auhthors on the research article are, Paige E. Davis, York St. John University, Lisa A. D. Webster, Leeds Trinity University, Charles Fernyhough Durham University, Helen J. Stain Leeds Trinity University Susanna Kola-Palmer University of Huddersfield.
**
Richard Emsley & Hanhua Liu, 2013. “PARAMED: Stata module to perform causal mediation analysis using parametric regression models,” Statistical Software Components S457581, Boston College Department of Economics, revised 26 Apr 2013.