Kevin Ralston, York St John University 2018
Like me, sociologists I have worked with tend to place occupation as of central importance in their examinations of the social world. This underscores a belief in the prominence of occupation as an indicator (and often determinant) of outcomes in people’s lives. This belief is not necessarily shared by those from other disciplines.
I was fortunate to be involved in a recently published work which estimated mortality in the UK by occupational group[1]. The research was led by Dr Srinivasa Vittal Katikireddi. The field for which the analysis was undertaken was public health.
A response, published in the Lancet, to our article, asked the question ‘why choose occupation as the category for analysis? Why not, for example, analyse according to main hobby, or main place of shopping? The answer is partly because occupational data are available’ (Jessop 2017). The piece argued that categorising people by their main job is ambiguous and that other classifications may produce more useful insights, suggesting alternative measures based on hobbies or shopping location may be preferable.
It is certainly possible to hypothesise causal pathways between shopping habits or hobbies and mortality. If we knew the average saturated fat content of the weekly shop we could predict an increased likelihood of a number of diseases and begin to think about specific public health interventions to influence levels of fat consumption. Similarly, whether people regularly participate in fun habits that involve groups and/or physical activity correlates with mental wellbeing and physical health. Knowledge of factors that stimulate involvement in sports or social networks can be used to improve health outcomes.
That being said, it is unlikely that general measures of hobbies or place of shopping would tell us more than if we know an individual’s occupation. A paper by Connelly et al (2016) describe occupation as the ‘most powerful single indicator of levels of material reward, social standing and life chances’. Indeed, occupation is likely to be a reasonable proxy of hobby types and is associated with shopping habits. What is more, people’s hobbies and shopping habits are outcomes influenced by occupational position. We know that social class background idicates whether people shop at Waitrose, play violin or are a member of a golf club. On the other hand it is difficult to imagine a realistic scenario where shopping at Sainsbury’s, being a keen angler or involved in a book club could have systematic influence on whether people are employed as teachers, carers or medical doctors.
The ongoing importance of public health analyses based upon occupation could be defended on a number of bases. Occupational analyses have a grand, long-run and robust theoretical underpinning. This is something categories such as hobby or favoured supermarket do not offer. This blog will not take the direction of constructing an argument in favour of occupation based on theory. Instead it will make a short general empirical justification in support of the use of occupation in public health analyses. I am (May 2018) working on a follow up paper to our research examining mortality by occupation. I thought I’d take a break from this to present a small piece of analysis which demonstrates something of the strength of association between an occupationally based measure and mortality.
Data
The data are from the ONS Longitudinal Study (LS) which contains linked census and life events for a 1% sample of the population of England and Wales. The LS has linked records at each census since the 1971 Census, for people born on one of four selected dates in a calendar year. These four dates were used to update the sample at the 1981, 1991, 2001 and 2011 Censuses. Life events data are also linked for LS members, including births to sample mothers, deaths and cancer registrations. New LS members enter the study through birth and immigration (if they are born on one of the four selected birth dates). From these data we have taken a sample of those present at the 2001 Census only. Death of a sample member is linked from administrative records. The outcome variable is age standardised all-cause mortality rate (per 100,000 person- years). The sample are men aged 20-59 years. Additional information on the sample can be found in the paper.
Occupation was self-reported in the 2001 census, in response to the question “What is the full title of your main job?”. Responses to this question were used to derive Standard Occupational Classification (SOC) 2000 codes that are readily available in the data. The follow up period for death was until 2011. Because of disclosure control issues we used SOC at three digit ‘minor’ level. There are 81 occupational groups coded at this level, we were able to report on 59 of these. From this we calculated European age standardised mortality rates and 95% confidence intervals by occupational group. The three digit SOC codes were used to apply a CAMSIS score to the occupational group. CAMSIS is an occupationally based measure of social stratification in the form of a scale of social distance and occupational advantage. More advantaged occupations score more highly on the scale, which ranges from 0 to 100 and is designed to have a mean of 50 for the general population (if you have not heard of or used CAMSIS before I suggest you check it out HERE, I highly recommend the measure).
Results
Figure 1
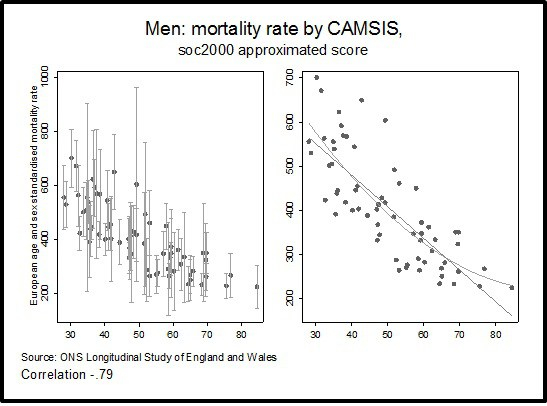
Figure 1 describes the relationship between CAMSIS and the mortality rate. The first graph shows estimated mortality with confidence intervals for the occupational group. The second shows only the point estimates for the occupational group, a linear fit line and a quadratic curve of the association with mortality. A strong correlation is evident between CAMSIS and the mortality rate (-.79). Although there is a deal of overlap in confidence intervals for many occupations, the pattern of association is clear, more advantaged occupations tend to have lower estimated mortality.
Conclusion
Correlation is not causation. Occupation in conjunction with all-cause mortality is limited in terms of its utility in ‘explaining’ the gradient in mortality observed. The estimated differences will be due to a range of factors, many of which are not directly applicable to the occupation, but which may be materially associated. That being said, it is certainly possible to identify direct testable hypotheses based on occupation. For example, recent work has shown that it is likely that firefighters experience increased rates of cancer because of contaminated equipment. This built upon more general work noting a higher incidence of cancer amongst firefighters. Questions I often wonder about, but have not had time to take further include: what is the risk of serious respiratory disease to delivery drivers who work in large cities versus those in rural areas? Are those in the new gig economy disproportionately affected?
These are points similar to those made by Jessop in commenting on our article. Nevertheless, it is necessary to firmly rebut the idea that we study occupation simply because it is what is available (whilst measures of hobby or favoured grocery shop are not). The small piece of analysis here demonstrates something of the magnitude of the association between an occupationally based measure and a measure of mortality. This is in line with Connelly et al.’s (2016) description of occupation as the ‘most powerful single indicator of levels of material reward, social standing and life chances’. There has been a long history of interdisciplinary overlap between sociology and public health. There is great potential for research drawing sociologically upon occupation as a basis for analyses of public health outcomes. Far from being a category that should be replaced, I would suggest occupation remains under exploited in public health research.
Acknowledgments
This study received no specific funding. SVK is funded by a NHS Research Scotland Senior Clinical Fellowship (SCAF/15/02). SVK and AHL are funded by the Medical Research Council (MC_UU_12017/ 13 & MC_UU_12017/15) and Scottish Government Chief Scientist Office (SPHSU13 & SPHSU15). DS is funded by the Wellcome Trust Investigator Award (100709/Z/12/Z) and the European Research Council (HRES-313590).
The permission of the Office for National Statistics (ONS) to use the Longitudinal Study is gratefully acknowledged, as is the help provided by staff of the Centre for Longitudinal Study Information and User Support (CeLSIUS). CeLSIUS is supported by the ESRC Census of Population Programme (award reference ES/K000365/1). The authors alone are responsible for the interpretation of the data.
Statistical data from ONS is Crown Copyright. Use of the ONS statistical data in this work does not imply the endorsement of the ONS in relation to the interpretation or analysis of the statistical data. This work uses research datasets that might not exactly reproduce ONS aggregates.
[1] The paper was also co-authored by Prof Alastair H Leyland, Prof Martin McKee and Prof David Stuckler


 Note: Youth Cohort Study of England and Wales, Cohort 6; All pupils gaining a GCSE passes at grades A–G; n = 14,281; Posterior probabilities and prior probabilities reported as percentages. Reproduced from Playford and Gayle 2016, Table 5 p.156.
Note: Youth Cohort Study of England and Wales, Cohort 6; All pupils gaining a GCSE passes at grades A–G; n = 14,281; Posterior probabilities and prior probabilities reported as percentages. Reproduced from Playford and Gayle 2016, Table 5 p.156.